






|
|
|
Wet or Dry Sampling for Digital Organs?
Colin Pykett
Posted: 20 April 2010 Last revised: 4 June 2014 Copyright © C E Pykett
Abstract. This article considers the two main techniques for recording (sampling) real organ pipe sounds when creating waveform sample sets for use in digital organs. These are either recorded 'wet' so that the ambience of the recording room is captured, or 'dry' so that it is not. The pros and cons of both methods are discussed in detail by considering room ambience including reverberation and colouration, ambience conflict between the recording and reproducing rooms, various aspects of phase interference during recording and reproduction, differences between signals recorded by a microphone and those perceived by a listener at the same position, and artificial reverberation produced by commercial effects processors. It is concluded that, although there seems to be no overall winner for all applications, one technique will sometimes be better than the other in particular situations. Therefore, as with other aspects of digital organs which can only imitate the real thing at best, only the user can decide which of the two options is most attractive for a given application. Hopefully this article will assist in making the choice.
Contents (click on the headings below to access the desired section)
Phase interference during recording
Phase interference during replay
Artificial Reverberation and Effects Processors
Polyphony implications of wet sampling
Memory implications of wet sampling
Phase and amplitude alignment at key release
When the sounds of real organ pipes are to be sampled (recorded) for use in a digital organ, the question arises whether they should be recorded 'wet' or 'dry'. (Like several others, these terms are explained in the Glossary at the end of this article, and their entries can also be accessed by clicking on the first appearance of the word in the text). The question is just as relevant to organs which synthesise waveforms using various real time modelling techniques as it is to those which replay the recorded waveforms themselves (sound samplers). For example, organs using additive synthesis operate on the harmonic structures of the sounds to re-create the original waveforms which are then passed to the loudspeakers. Deriving the harmonic structures in the first place requires the original recorded waveforms to be subjected to an offline spectrum analysis beforehand, and it has to be decided whether to analyse wet or dry waveforms because their harmonic structures will differ for reasons explained later. Organs using physical modelling will often require a waveform sample set to be available to the designer, particularly if it is desired to simulate a particular instrument, if only to reassure her/him that the sounds produced by her/his voicing efforts turn out reasonably close to the real thing. In this case also, it has to be decided explicitly what type of ambience is to be simulated by the model. Even those organs whose voicing has been 'invented' from scratch, such as those which use synthetic waveforms not based on those of actual pipes, will have their sounds modified by the ambience of the listening room in ways which are discussed presently. Therefore nothing in this article relates exclusively to any particular type or brand of digital organ because the issues to be discussed are generic to all of them in one way or another. Another general point which needs to be made at the outset is that no attempt will be made to illustrate that either technique (wet or dry sampling) is universally 'correct' or 'better' than the other when taken in the round. They both have advantages and disadvantages which make one method better for some applications but the alternative one more suited to others. However, even this choice has to be made on the basis of subjective as well as objective criteria, therefore it is up to the user in the last analysis to make the decision.
A major issue which influences whether we use wet or dry sampling is to do with the ambience of the room in which the digital organ will be played. If it is small with a dry acoustic, the recorded ambience from the auditorium in which the pipe organ resided can be advantageous, though it can also turn out to be a problem which cannot be rectified. This is because, although it is a common psychological experience that one's initial reaction is positive, after a while one sometimes wishes one could 'turn the reverb off' and have the effect of an instrument more compatible with the actual room one is playing it in. This forms part of the subject of 'ambience conflict', of which more later. On the other hand, if the digital organ is to be played in a large room with its own distinct ambience, superposition of the different recorded ambience enshrined in wet samples can cause aural confusion to the player and the audience. In this case it can sometimes be better to use dry samples. The use of dry samples in either situation can also offer more flexibility than using wet ones in that artificial reverberation of any sort and to any desired degree can be added to them if desired. But here resides yet another problem, because some users dislike artificial reverberation systems, whether implemented as separate boxes of studio hardware or VST (virtual studio technology) software on a computer. Thus, as mentioned above, because there is no universally 'correct' choice which can be applied to all circumstances, we have to take each situation on its merits as it arises. In practice this usually means that we either want the ambience of the room containing the original pipe organ to be imposed and retained on the recorded sounds, including the reverberation decay when notes are released, or we don't. Thus the decision is largely subjective - I want it or I don't - but it raises a large number of other issues both subjective and objective. These include spectral distortion due to colouration, phase interference, electronic and acoustic signal mixing effects, and the major issues of artificial reverberation derived from effects processors, stereophony, binaural recording and surround sound. All these are discussed in the article, though it has not been possible to write it as one continuous narrative flow. Each topic is to some extent disjoint and independent of the others, thus it has its own section rather like a chapter in a textbook, and only at the end is an attempt made to wrap the whole lot up to extract some overall conclusions.
Because entire libraries could be filled with countless books dealing with these topics, it is obviously going to be impossible to distil things down so they can be covered here in a manner which will suit everybody, especially as so much of the material is subjective. Moreover, some digital organ manufacturers have devoted much effort to their particular way of doing things, particularly in view of the considerable investment in time and money in producing a high quality sample set, either wet or dry. This investment may not be recoverable if potential customers want the alternative type (e.g. if they realise that the 'wetness' in a wet one cannot be switched off, or if they dislike artificial reverberation applied to a dry one, etc). This seems to affect the judgement of certain manufacturers because the issue assumes a high profile with some of them. This was demonstrated clearly when a firm offered me one of their products free of charge as an inducement to join the fray on their blog. I declined the offer but joined the fray anyway, but because they apparently disliked what I said their response became singularly offensive and unwarranted. Therefore there does seem to be a need for an objective clarification of the issues, hence this article.
The acoustic ambience we perceive in a room arises largely because of reflection, scattering and absorption at its surfaces, which can also be modified depending on how they are treated or what they consist of. For example, carpeted floors cause the ambience of a room to be strongly modified. Account also has to be taken of acoustic screening and diffraction by objects within the sound field. (Note that the word 'room' is used here generically to denote an auditorium of any size, ranging from a cathedral to a domestic bathroom). This is not the place for a detailed treatment of ambience or room effects in general because there is not the space to do justice to it, but a good account aimed at musicians at a non-mathematical level was given by Benade [1]. Owing to reflection and scattering, the (different) sound arriving at each ear is the sum of the direct sound wave from a source such as an organ pipe, plus a very large number of waves resulting from reflections at the walls, floor and ceiling. All objects in the room, such as the pillars in a cathedral, will also either absorb, reflect, scatter or diffract the sound impinging on them. Only if the room is anechoic will there be no reflections and similar boundary effects, and in this case we will hear only the direct wave from the sound source. But no ordinary room, no matter how small, is anechoic unless it is specially treated to be so. It is also important to realise that 'dry' does not mean 'anechoic'. A small but otherwise ordinary room such as those we find in modern houses, although it will usually have a dry acoustic, is not anechoic because there will still be a huge number of reflections from its boundaries and other effects due to furniture, etc. This means that it will, at least, impose some degree of colouration on the sounds in which particular frequencies or frequency bands are enhanced or attenuated. Thus a pair of loudspeakers in a small room with a dry acoustic does not even come near to listening to the signals through stereo headphones as often assumed. This is because each loudspeaker radiates sound directly to both ears in a way which headphones do not and cannot, even if the room were anechoic. Moreover, because real rooms are not anechoic, the sounds from loudspeakers will always be modified by the room ambience before they reach our ears in ways which do not apply to headphone listening. The misunderstanding presumably arises because the subjective lack of echoes and reverberation in small rooms leads to the assumption that no reflections take place, and thus that the rooms are therefore virtually anechoic. In practice, a small, acoustically dry room will still modify sounds radiated into it from loudspeakers, sometimes dramatically, because of phase interference between the many reflected waves and because of absorption, diffraction, etc. All these effects lead to phenomena such as colouration and they will be discussed in more detail later, but for now it is important to bear in mind that a small room with a dry acoustic cannot be used as a listening environment from which to draw general conclusions about the relative merits of wet or dry sampling. Such a room, indeed any room, can only be used to draw highly specific conclusions about those relative merits as they relate to it, and it only.
Narrowing the discussion to focus a little more on reverberation, rooms can be classified in one of two ways as far as reverberation is concerned – 'small' or 'large'. There are also any number of intermediate categories, but for present purposes we shall deal only with these two. An acoustically small room has few, if any, distinct echoes which can be separately identified as such by the ear. When the sound begins it is almost immediately perceived because of the short propagation distances concerned, and thereafter it reaches a steady state so rapidly that the time involved (the duration of the acoustic impulse response of the room) is perceptually negligible. When the sound ceases, the reverberation decay begins almost immediately, it is smooth, of short duration and close to exponential in amplitude against time. By contrast, an acoustically large room returns initial discrete echoes which can often be separately perceived by the ear before they begin to merge with each other prior to the sound field stabilising, which can take several seconds in this case. In particular, the delay between the direct wave arriving from the source and the first echo is often easily perceptible in a very large building. When its source is subsequently cut off, the sound decays more smoothly than during the attack phase, again close to exponentially but of longer duration than for small rooms. However even the decay phase in this case tends to be 'lumpy' and not so smooth as for small rooms. Therefore these differences are mirrored both in the perceived attack characteristics of the sound as well as its release. Although it is difficult to verbalise and explain these phenomena in detail at a subjective level, few will have any hesitation in deciding whether a room is acoustically large or small from its effects on sounds. Note that the sound of a steady source such as an organ pipe will eventually reach a stable state even in the most reverberant room if it lasts for long enough. In that situation the amplitude and phase of its waveform become stationary (stable) with time, which means that its waveshape at any given position will not change with time thereafter until the sound source ceases. In turn, this means that the amplitudes and relative phases of all of its constituent harmonics will have stationary amplitudes and phases as well. In particular, note that reverberation does not impose any frequency shift on the sound, no matter how complex the reverberation characteristics might be (unless objects such as people are moving around in the sound field and thereby generating continuous phase shifts due to the Doppler effect). During the stationary state, the amplitudes and phases of the harmonics of an organ pipe received at any location in the room are determined not only by the sound emitted by the pipe itself but also by the ambient characteristics of the room.
Whether a room is 'large' or 'small' affects the design of a synthesiser which is to be capable of simulating wet samples. When the reverberation time is long, as in a 'large' room, the duration of the sound can influence the nature of the ambience which is heard. For instance, if the organist holds a note or chord for a period comparable to or greater than the reverberation time, the sound when it dies away will generally be perceptually different than if the notes were released quickly. This is because, in the latter case, the reverberant sound field will not have had time to stabilise during the shorter sustain period. Thus short staccato notes in a highly reverberant building will often result in noticeable discrete echoes when the notes are released, whereas these echoes are not heard when the notes are sustained for longer periods. This gives rise to the 'lumpy' attack and release behaviour of large - room ambience mentioned above. Simulating this behaviour electronically involves the sampling and storage of multiple release transients corresponding to different sustain times, together with a separate release point on the steady state waveform associated with each one. Even so, this can obviously only represent an approximation to the indefinitely large number of sustain periods possible with the original organ in the original room, and it calls into question the desirability of trying to simulate both the instrument and its acoustic environment simultaneously by the one synthesiser. So the definition of 'large' or 'small' therefore depends largely on the ability of the ear and brain to perceive distinct echoes, to assess the degree of spectral colouration imposed on the sound and to form an impression of the attack and decay times. It does not involve a precise definition of 'size' in an architectural sense, though there is obviously a qualitative correlation between the two. There is argument over the minimum time for which subjective echo resolution by the brain is possible, but it is around 10 – 30 msec. This agrees with the observed fact that speech starts to become less intelligible in rooms with strong discrete echoes which are separated by about 35 ms or more, and I could tell you of a conference room in a new and expensive building where I once worked which was never willingly booked by staff convening meetings for this reason (interestingly, it was called 'the cathedral'). It follows that the size difference between acoustically large and small rooms is that large ones have boundaries which result in delays around 30 ms or more, i.e. their separation is about 10m (33 feet) or more. This is only a rough ball park figure, but it shows that domestic rooms generally are 'small' in reverberation terms, whereas anything with walls separated by much above the 10m figure is starting to become 'large'.
Another factor which is not always appreciated is that ambience is not a unique and unambiguous property of a room because it varies from point to point within it. Therefore the perceived ambience at one position is not the same as at any other, because the manner in which the direct sound wave from the source plus all the myriad reflections combine is governed by their amplitudes and phases at the listening position, and these are influenced by simple geometry. This means that, as one moves around any room (or changes the position of microphones), the amplitudes and phases of each frequency component existing in each of the huge number of ray paths vary. In turn, this affects the way the sound rays add together at each ear or at each microphone. It therefore begs the question of why any one position is necessarily subjectively better than any other, either for listening or for recording, because they are all different. Among other things, each position implies a different colouration imposed on the sound by the building. Therefore different listeners will express a range of preferences for listening position, a phenomenon easily observed by the way audiences distribute themselves when taking their seats before a concert or recital, or the way some move to different seats during the intervals. This means that the lack of choice imposed on all users of a wet sample set (because of the immoveable positions of the recording microphones) is something which not everybody will welcome, if only as a matter of principle. This is unlike a dry one which can be modified to taste using artificial reverberation in a small room, or it can be radiated directly into a large one and therefore allow listeners to select their own listening positions.
If recording wet samples, it is useful to consider who will be using them because this affects microphone positioning. If the user will play the simulated organ him/herself, as opposed to listening to someone else play it, this will usually mean that the microphones should be placed at or close to the console of the pipe organ. It would seem to defeat the object of capturing room effects in most cases if the simulated organ has a markedly different ambience to that which would be experienced when playing the original pipe organ. Thus one would not usually choose to record wet samples from a cathedral organ at at some arbitrary position halfway down the nave, say, if the console was many metres away in a loft above the choir stalls. Such sample sets can sound distinctly odd to the player of a digital organ - one professional organist (who was thoroughly familiar with the original pipe organ) complained to me recently that a digital simulation of it using a wet sample set recorded in this manner sounded as though he was "hearing a CD of the damn thing and not playing it at all"! This illustrates the potential for a significant psychological mismatch between the real and the virtual instruments if the recording positions are not chosen carefully.
Note that there is an important difference between listening as a human being on the one hand and recording using microphones on the other, and this concerns our ability to move. This is particularly true if the human in question is the organist, because her/his head is constantly moving by amounts far greater than those which would usually occur if s/he was merely a member of the audience. Quite small movements can result in large phase changes in the received signals at the ears. For example, at 524 Hz (8 foot treble C) a movement of only 1.8 mm within the sound field results in a phase change of about one degree along any ray path, therefore moving one's head by 300 mm (about one foot) results in a phase shift of 180 degrees at this frequency. This means that a phase reinforcement at one position can become a phase cancellation at the other, with the potential for major changes on the perceived sound. The effects become more critical and pronounced at higher frequencies because a given head movement results in correspondingly larger phase shifts. These effects unconsciously form part and parcel of one's subjective playing experience at an organ, and if they are absent (as they will be when the sample set was recorded in another room using microphones fixed in position), the experience will be different at least when playing the simulated organ, and unsatisfactory at worst.
These factors just discussed, the ambiguousness of room ambience with position and human listening versus microphone recording, are not mere academic niceties because they profoundly influence the sampling process. This is demonstrated by an example of the varying sound signal from a moving microphone which can be heard in the clip below. It was captured while moving the microphone around before selecting its final position prior to a sampling session, which explains the miscellaneous noises which can also be heard. The organ stop was an 8 foot manual reed (a Trompette en Chamade), and the recording is monaural because only one microphone signal is reproduced here. The peaks and nulls of the acoustic phase interference pattern in the building can be heard clearly as the microphone moves through them, and these give rise to distinct changes in tone quality (timbre) as the amplitudes of various harmonics are modified. These effects would also be imposed on the signals received by the ears of a moving listener, but they are usually less subjectively noticeable in this case for the important reasons discussed later.
So what is the answer to the question posed above - which of the many microphone positions in this short example was the best one for making the recordings? There is, of course, no unique answer. Consequently there is no such definitive thing as "the sound" of a recorded organ pipe! The best one can do is to capture "a sound", especially for wet sampling.
More often than not, conflict between the ambiences of a recording room and that in which the recordings are later replayed makes it impractical to reproduce the original ambience convincingly. Once the early excitement of stereophony on recorded material (vinyl or analogue tape in those days, the 1950's) had worn off, people began to realise that it was impossible to accurately reproduce the ambience of one room in another for most practical purposes. The best that could be done was to convey a subjective impression of a large room such as a concert hall in a smaller one, such as those found in most houses. Of course, few will deny that the effect is worth having, because one only has to listen to a recording reproduced monaurally to notice the difference. However it is a mistake to believe that the effect of twin-channel stereo, or surround sound using more than two channels, is anything other than a pleasing illusion because it is invariably artificial to some degree. One can never make a domestic living room sound indistinguishable from a cathedral, say, except in one special case, and this applies to digital organs using wet sample sets in just the same way as it applies to stereophony in general.
Unfortunately this special case is impractical for all intents and purposes, especially for digital organs, but it will be described because it illustrates some important issues. It relies on the obvious truism that if one can exactly reproduce the waveforms at each ear drum (different to merely reproducing the waveforms outside the ears) in the listening room which existed at a given location in the recording room, then the ear will be unable to detect any difference between the two. In practice it is straightforward to achieve this fairly closely by making the recordings using a dummy head or bust with acoustic properties identical to those of a real one (desirably one's own), including the subtle but important acoustic effects imposed by the shapes of our outer ears (the pinnae). It is the latter which contribute strongly to our ability to extract three-dimensional information from only two acoustic channels, and their characteristics are well understood. Another factor is the cross-coupling between the two ears which occurs due to sounds impinging on one ear reaching the other having tracked externally round the acoustic shadow of the head itself. Likewise, these matters are also well understood. Thus by placing two small microphones at positions slightly within the dummy head corresponding to the two ear drums, and later reproducing the signals using stereo headphones (not, repeat not, loudspeakers), fairly realistic three-dimensional spatial reproduction and ambience of the sounds in the original recording room can be achieved (though it is still not perfect, partly because the listener's head movements do not affect the sound in this case and this confounds our auditory mechanisms by removing the important dynamic spatial cues which they expect to exist). This technique is called binaural recording, but it scarcely needs to be pointed out that it is impractical for use when playing a digital organ unless only the player is to hear it, because of the need to use headphones. Therefore, in practice, loudspeakers must usually be used and this brings us onto the topic of ambience conflict.
Ambience conflict arises because the speakers are producing their sounds at particular locations in the listening room, and they produce reflections, echoes, etc, within it. Thus the resulting ambience effects are now characteristic of sound being produced at these speaker locations rather than characteristic of the original pipe organ producing its sounds in the recording room. In many cases this is not simply a result of the physical dimensions of the room and the acoustic reflection properties of surfaces (walls, carpets, etc) but it also has resonant components e.g. resonances of the room itself and those of suspended wooden floors, closed cabinets, etc. There is thus a conflict between these two ambiences: the recorded ambience (assuming wet samples are used) and the listening room ambience. Similar conflict will occur for dry samples passed through an effects processor, though this can be adjusted within wide limits whereas the fixed ambience impressed on wet samples cannot. In either case the listening room ambience is subjectively dominant, since within the room your ears detect the sound actually coming from the loudspeakers plus all the reflection points, with all the associated amplitude and phase shifts, and with all the appropriate acoustic signatures produced by the acoustic shadow of your head, your ears, etc, all compounded dynamically by the way your move your head while playing the simulated pipe organ. It impossible to remove listening room ambience completely without making the room anechoic, which is usually impractical. Therefore, even with the best speakers and with the best room acoustic treatment compatible with the room still being usable for other purposes, the remaining room ambience still makes it next to impossible to produce a realistic subjective impression of a big loud sound source such as an organ, which one normally listens to from, say, ten metres away or more. In small rooms, if the sound level is correctly scaled, then it sounds like a miniaturised organ playing, say, three metres or so away or less, with the miniaturised image somewhere between the speakers. If the volume level is raised to realistic organ levels it is then often too loud to be subjectively and psychologically compatible with the miniature sound image, and because it is being produced in a small room with close-by internal reflections, it tends to sound hard and unpleasant. Thus, and regardless of whether the room is anechoic or not, the effect is usually unrealistic to some degree because it is artificial to pretend that one's living room is some cathedral or other. Humans are intelligent beings, and they cannot fool themselves into believing that one room is another solely on the basis of reproduced sounds. After a while some people wish they could switch off or modify the recorded ambience in these circumstances, but once it is there they cannot. Using dry samples with artificial reverberation in a small room at least gives one the opportunity to experiment with different settings when the almost inevitable dissatisfaction sets in with the current setting. In summary, the performance of all practical reproducing systems for digital organs is governed strongly by the acoustics of the listening room, and so these systems cannot recreate the original auditorium properly even when using wet samples. In the latter case they have most of the acknowledged deficiencies of conventional stereo systems, but with an important exception which is advantageous and this will be mentioned in a moment. With conventional stereo, some people cannot shake off the perception that the two individual speakers are making the noise and therefore they cannot perceive a stereo illusion at all. For them, the situation is no better with more than two speakers, which is one reason why surround sound had such a brief but exciting lifetime in the 1970’s and 80’s. Admittedly it has now made a comeback, with 7.1 surround sound and the like for computer games and home cinema, but in most cases the sounds being reproduced are not of anything approaching high fidelity, and they are often artificially generated in any case (e.g. dinosaurs in jungles, Lara Croft in a sports car, or one spotty youth slaughtering another). Such artificial scenarios have nothing to do with digital organs which strive to reproduce the sounds of a real instrument and we can therefore learn nothing from them technically.
The advantage mentioned above relates to digital organs but not conventional stereo reproduction. With the latter we have to take the recorded signals as they are and put up with the consequential problems. However, with digital organs, the fact that each pipe sample is recorded separately means that we can route the samples to any speaker we please when replaying them in the listening room, at least in principle. The consequence is that some otherwise unfortunate results due to phase interference in the listening room can be reduced or overcome, again in principle, and this will be discussed in more detail in a subsequent section.
Phase interference during recording
Phase interference occurs in a room because of reflections and scattering from its surfaces and it has been discussed elsewhere on this website [2]. Note that the word 'interference' is used here in its technical sense, as in 'interferometry', rather than in its everyday sense as in 'meddling'. It results in a number of effects including the augmentation or cancellation of particular frequencies at a microphone position. These effects can be partial or complete, in other words the microphone can experience a considerable enhancement of the signal amplitude or its complete cancellation as well as anything in between these extremes.
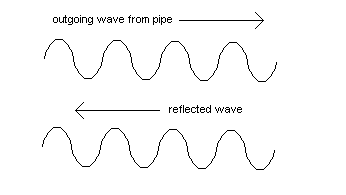
Figure 1. Two in-phase waves: their amplitudes add - the sound is louder
Augmentation of signal amplitude is illustrated in Figure 1. This shows a wave propagating away from an organ pipe together with another wave of the same amplitude resulting from reflection at a surface going in another direction. In this example the two waves are in phase so their amplitudes will augment such that the total amplitude is doubled. The augmentation effect will be less than a factor of two if the reflected wave has a lower amplitude than the direct one.
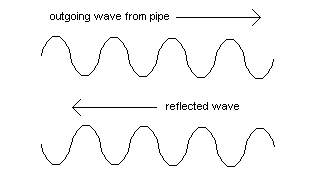
Figure 2. Two out-of-phase waves: their amplitudes cancel - the sound vanishes
Cancellation is shown in Figure 2 in which the two waves are in antiphase (out of phase by 180 degrees), and in this case complete cancellation will occur for waves of the same amplitude, whereas a partial reduction in amplitude will occur otherwise. As mentioned earlier in the section dealing with room ambience, the distance involved between the two cases is half a wavelength, and at medium and high frequencies this can be quite small (the example quoted previously was at a frequency of 524 Hz, corresponding to 8 foot treble C, in which half a wavelength is about 300 mm or one foot). A sound clip of the corresponding effects was also included in the earlier section.
Augmentation and cancellation effects occur independently for each harmonic of the sound once the reverberation within the room has stabilised, and the effect will be different for each harmonic. This is because the different wavelengths of each harmonic result in different phases at the position of interest. Also the amplitudes of each reflected harmonic wave will be different because of the different reflection, scattering, absorption and diffraction effects for each one (these effects are all frequency-dependent in general). Because the wave that is recorded at a microphone is the sum of all of its constituent harmonics, its shape will therefore differ from the waveshape of the direct wave from the organ pipe at the same microphone position that would be observed if the recording room was anechoic.
Although these effects will always occur at a microphone to some degree, do they occur at the ears of a listener in the same room? This is an important point which generates much discussion and apparently some confusion. Clearly the same effects would occur if one of the listener's ears were to be held at exactly the same place as the microphone, but the situation is artificially constrained in this case. In practice the conditions are different for a listener for two important reasons. Firstly, the listener picks up sound binaurally using both ears, and secondly s/he moves her/his head continuously within the sound field, particularly if the listener happens to be also playing the pipe organ in the room. At our previously chosen frequency of 524 Hz, maximum augmentation or cancellation will therefore not occur at both ears simultaneously owing to the size of the head even without head movements, and with head movements augmentation or cancellation will only occur transiently at one ear or the other from time to time. The net result is that cancellation or augmentation effects are not generally subjectively noticeable in this frequency range or above by a listener in the recording room. However there is also another important point to bear in mind. If the recorded signals are later replayed in a different room, each microphone feeding a single loudspeaker, the listener's head movements will no longer compensate subjectively for the phase interference effects in the recording room, because they cannot. The listener's head is no longer moving in the sound field of the recording room but in that of the listening room. This results in a set of quite different phase interference phenomena which are discussed later.
Only at much lower frequencies do we sometimes become aware that we happen to be at a position in the recording room where excessive augmentation or cancellation is taking place. An actual example concerns the organ in a certain English cathedral - when I played this instrument it was difficult to hear much of the fundamental of bottom C of the 32 foot Contra Violone pedal stop at the console, though it nevertheless caused much rattling of windows and furniture in different places in the building. Yet elsewhere in the compass where phase interference effects at the console were different, the fundamental was easily perceived. The reason why one can detect such effects at low frequencies is because the distances corresponding to a half-wavelength are much greater. Therefore the effects persist over distances greater than the separation of one's ears and those involved in head movements.
Phase interference effects on a wet sample set are sometimes noticeable when listening to the recorded signals from a single microphone. It is sometimes the case that the timbre (tone quality) of a single pipe sound will change abruptly when the note is released and the sound then goes into its release phase, which is of course dominated by recording room reverberation. At this point the ear sometimes notices how 'thin' the pipe sounded while the key was held down, yet it suddenly becomes much richer in tone when the sound rolls away after key release (or vice versa). The reason is due to the phase interference obtaining at the microphone while the note was sustained, the effects being suddenly modified at key release because (among other things) the direct wave from the pipe vanishes abruptly. Anyone who has prepared a wet sample set will probably have noticed this. As mentioned above, the severity of the effects perceived by the same listener at the time s/he was previously making the recordings would probably have been considerably less noticeable, because of the beneficial effects of binaural listening and the freedom to make unconscious head movements. In such a case it has to be decided whether the sample in question should be used or rejected.
There will always be some degree of sudden modification of tone colour of the signal from a single microphone at key release, the important point being whether the amount of it is subjectively acceptable or not. The following monaural sound clip demonstrates the effect for a 16 foot pedal reed (a Trombone stop), and in my opinion this verged on the unacceptable - careful listening demonstrates that much of the high frequency character of the tone was lost while the pipe sounded, whereas it appeared briefly at key release. On the whole, pipe tones simply do not sound like this to a listener in an auditorium for the reasons mentioned above, and it is an issue which can degrade the fidelity of a wet sample set. In this case it turned the sound of a beautifully voiced reed into little more than a foghorn.
Now consider what happens if the two waves in the previous discussion are at slightly different frequencies. This cannot occur if they originate from the same pipe, one being the direct wave and the other a reflected wave. However it will often occur for waves from two pipes of notionally the same pitch, such as two diapasons on the great organ, owing to tuning drift. In this case the two waves move slowly but continuously in and out of phase at a rate corresponding to the beat frequency between them. Therefore we will hear a slow wavering effect, which is in fact the phenomenon used by tuners to bring the two pipes into tune. The slowest 'waver' occurs at the lowest frequency of the sound, i.e. at the fundamental frequency, with correspondingly faster 'waver rates' for the higher harmonics. (These simultaneous but different beat rates for each harmonic in organ pipe sounds can easily be heard in most cases). If the two waves each have a particular harmonic with identical amplitudes at the microphone position, there will be complete cancellation of this harmonic once per beat cycle at the listening position (the beat cycle having a frequency corresponding to the harmonic in question). Although this undesirable effect would indeed be picked up by a microphone if the two pipes sounded simultaneously, it would not be so pronounced to a human listener for the same reasons as before. Although the listener would still hear a beat at this harmonic frequency for the two pipes, complete cancellation of the sound for her/him does not take place at medium to high frequencies for two organ pipes beating in a real building, though it can occur at low frequencies (again for the same reason as before). Of course, when recording a sample set, the two pipes would usually not sound simultaneously because they would be recorded separately. However, if they were to be replayed together when the simulated organ was played in the listening room, exactly the same undesirable phase interference effects would be heard if the two signals were fed to the same loudspeaker and this problem is discussed in the next section.
Therefore the important point to take away from this discussion is that undesirable phase interference effects resulting in complete or near-complete cancellation of particular harmonics, or even of the complete waveforms themselves, can be impressed on samples recorded using a microphone, even though a listener at the same position in the same room will seldom perceive the effects so strongly. This has to be taken into account when deciding how best to reproduce the samples through the loudspeakers of a digital organ in a different room. In other words, wet sampling is not the same as a human listening to the same instrument at the same position in the same recording room because (a) in practice the perceived phase interference effects are different for the two cases of microphones and human listeners in the recording room, and (b) an entirely different set of phase-dependent effects are set up when radiating the signals in the listening room. The net result of all this is that a formidable set of problems have to be addressed and minimised when designing the loudspeaker system for a digital organ in the listening room. This reproduction problem will now be discussed.
Phase interference during replay
In another article elsewhere on this site I raised the problem of phase interference during reproduction in the listening room as a topic called 'signal mixing' [3], and it has led to much correspondence and discussion over some years. Therefore it will also be discussed again here using the original material because of its significance. We have just seen that certain signals recorded by a microphone can be considerably augmented or attenuated, an effect which would not be so subjectively noticeable to a listener at the same position in the recording room for the reasons mentioned. However in the listening room, a listener (including the player of the digital organ which is using the sample set recorded in the original room) can no longer rely on these same factors to reduce the worst perceived effects of phase interference. This is because the recorded phase interference effects are now enshrined as part and parcel of the sample set recorded at a given microphone position - we are now stuck with them. Therefore any beneficial effects due to binaural perception and head movements on the part of the listener and (particularly) the player can now only be applied to the sound field in the listening room rather than in the recording room. It therefore becomes important to take this into account when deciding how best to minimise the undesirable effects of phase interference in both rooms when radiating the sounds into the listening room using various loudspeaker configurations.
All current digital organs require many different signals to be mixed down before feeding them to a relatively small number of loudspeakers. The signals represent all the notes of all the stops which are currently being played. For example, if a chord of four notes is played on a combination of eight stops, there are 32 separate signals being generated within the organ system. Only the most expensive organs would have this number of loudspeaker channels, and then rarely, therefore the software inside the organ's computers has to decide which signals are fed to which loudspeakers. When more than one signal is fed to one loudspeaker it is necessary to mix the various signals electronically first.
More often than not this produces an artificial and objectionable result, because electronic mixing often introduces distortion of the timbres (tone qualities) of the various signals being mixed. This is because of phase interference at similar frequencies in the various signals as explained already. For example, consider the case mentioned already where two unison diapasons are drawn. These will have similar timbres, which is the same thing as saying that their frequency spectra will be similar with similar numbers of harmonics at identical frequencies. Electronic mixing results in a composite signal at each harmonic frequency which depends on the amplitudes and phases of the original harmonics. The result is a corresponding harmonic in the mixed signal which might bear little resemblance in amplitude to either of the original harmonics. Therefore the composite sound of the two diapasons when mixed electronically into a single waveform will often bear little resemblance to either of the two original sounds. Often we will hear a degraded sound similar to that sometimes picked up by a microphone if the two signals (organ pipes) had sounded simultaneously in the recording room.
Generally the result is even worse than this, because the fundamental frequencies (and therefore the harmonic frequencies as well) of the two signals in this example will usually be very slightly different. On the face of it this is a good thing, because the frequencies of two real diapason pipes will never be exactly the same in a pipe organ either. Such frequency offsets are introduced deliberately in digital organs using synthetically generated waveforms (as opposed to recordings of real pipes) to imitate this effect, and provided the two signals in this case are always fed to separate loudspeakers, there is little or no problem. However if they are mixed electronically before being pushed through a single loudspeaker, their slight mutual de-tuning will become apparent as the fundamentals and all the harmonics drift in and out of phase with each other.
Why does this effect not occur when mixing occurs acoustically, that is, when two sound signals from two or more loudspeakers are allowed to mix naturally in the listening room? The reason is that there are myriad reflections in any room, even the smallest one, and acoustic phase interference in the resultant complex sound field at any frequency is never as severe as the phase interference when electronic mixing is done. Moreover, the beneficial attributes of binaural perception and unconscious head movements which apply to a human listener in the recording room have been explained at length, and these will also apply in the listening room when acoustic mixing is used so that the worst extremes of phase interference will not be experienced - but only, repeat, only, when the acoustic properties of the listening room are able to be exploited by the listener through the use of separate loudspeakers to radiate the various signals.
Demonstration of the signal mixing (phase interference) problem
For those who have had difficulty following this so far, I sympathise. It is tricky to get your head round it. Because most people experience this at first when initially exposed to the problem, it might be helpful to demonstrate the situation with a real example which you can listen to if your computer is set up to download and play mp3 sound files in stereo. Either loudspeakers or stereo headphones can be used. I set up two 8 foot diapason tones in a digital organ, both notionally sounding middle C. However the frequencies of the two differed by one cent (one hundredth of a semitone). This small amount of de-tuning is representative of what would be heard in a pipe organ, and it results in a very slow beat between the two sounds. The samples in this example are dry, but this is irrelevant because exactly the same effects would arise if they had been recorded wet (provided the recording was long enough to allow the reverberant properties of the recording room to stabilise).
If you click on the 'stereo' link below you should hear the two diapason sounds issuing from the two separate audio channels of your computer. In this case the signal mixing is being done acoustically in your listening environment (or in your brain if using headphones), and although the slow beats between the two tones can be detected, it is not objectionable. Indeed, it sounds quite natural and it assists the ear in determining that two sound sources are present. Note the file was recorded at a fairly high level, therefore do not have the volume of your audio system set too high.
By modifying the software I then mixed the same two signals electronically, just as a digital organ is sometimes forced to do because of insufficient loudspeakers. The resulting mono sound file will play monaurally into both channels of your audio system if you click on the 'mono' link below:
Notice in this case how the beats are very much more pronounced, and how the timbre of the single composite tone varies over a beat cycle. In particular notice how the fundamental vanishes completely owing to phase cancellation at one point in the cycle. These effects are of course completely unnatural and highly objectionable, yet they occur to some extent in every electronic organ ever made no matter how expensive or how heavily promoted. This is simply because there are never enough loudspeakers to cater for the number of signals which can be generated simultaneously. In particular, note that the beneficial effects of binaural perception and head movements on the part of the listener are now irrelevant with this second example. You can move your head around like the proverbial nodding donkey in your listening room, yet you will not be able to modify the gross phase interference effects emerging from the loudspeakers. Once they are there, they are there, regardless of whether wet or dry samples had been recorded. It is true that if the sample set had been recorded in stereo and two speakers were used for replay, it is unlikely that such a gross phase interference/signal mixing problem would apply to both. However the ear will quickly latch onto the fact that the problem exists in just one channel, and therefore this will still degrade the effect of the digital organ when played in the listening room through an insufficient number of speakers. The problem gets subjectively worse as more stops and notes are combined in full combinations, and it is a major contributor to the well known problem that digital organs sound progressively less satisfactory under these conditions.
The problem will only go away completely if there are as many independent loudspeaker channels as potential signal sources in the digital organ, in other words one needs as many speakers and speaker channels as the polyphony figure of the instrument. This is unattainable and a compromise has to be sought, as discussed in detail in the other article already referred to [3].
Colouration is the distorting effect (in the sense of altering) imposed by a room on the sounds emitted into it by a source such as an organ pipe when those sounds are auditioned by a microphone or a listener at some location remote from the source. For the purposes of this article the distortion is frequency-related in that it affects the frequency spectrum of the emitted signals. Thus some harmonics, or groups of harmonics, will be modified in amplitude relative to their neighbours in a way which would not occur to the same extent if the room was anechoic. Some colour is often subjectively attractive, and one of the advantages of wet sampling is that an impression of the colouration of the original building can be retained when those samples are replayed in a digital organ. Like reverberation, colouration is part of the ambience of the recording room.
There
are several factors which contribute to colouration. One, already
described, is due to the phase interference effects between the multiple waves
travelling in different directions which occur at the listening position or at a
microphone. We saw that phase interference augments or reduces particular harmonics, sometimes
dramatically. It is similar to reverberation in that it would not exist if
there were no room reflections, that is, if the room was anechoic. Another
contributor to colouration is simply the
distance between a listener or a microphone and the sound source. Unlike
phase interference, its effects are independent of whether reflections occur or
not, and therefore it would occur even in an anechoic room. Because
high frequencies are attenuated in air more rapidly than low ones with distance, even
in an anechoic room, it
imposes a low pass filter on the emitted sound which contributes to colouration.
Therefore, artefacts in the original pipe sound with high frequency components, like wind noise and some features of the attack transients, will either not be heard at all beyond a certain distance, or they will sound different at different distances. This feature also affects the perception of sudden-ness in the onset of sounds, because if the higher frequencies are filtered out due to the low pass filter effect, the subjective effect is one of less sudden-ness.
Artificial Reverberation and Effects Processors
Artificial reverberation is usually not appropriate for use with wet samples because of the unsatisfactory conflict which arises between the recorded ambience already impressed on the samples and that produced by the effects processor. Ambience conflict has been discussed already. Nor is it usually appropriate for dry samples if they are used in a digital organ situated in a room with a sufficiently attractive acoustic of its own. Therefore its use is generally restricted to situations where dry samples are used in rooms with an excessively dry ambience, such as the small rooms in most houses (although artificial ambience modification systems are being used increasingly often in concert halls which have unsatisfactory reverberation characteristics). In these circumstances artificial reverberation has advantages, such as the ability to control the reverberation characteristics within wide limits, but it also has disadvantages such as the technical limitations which apply to all current effects processors, and these will now be discussed.
Simulating reverberant spaces is difficult, partly because it is impossible to characterise and thus parameterise them unambiguously. One reason for this is that the reverberation characteristics of any room are different for all points within it. Since there is something approaching an infinity of points, there is also a near-infinity of different ways in which the simulation can be done. Therefore one has to be able to answer the question: which point in the hypothetical room is the one where one wants the reverberation simulation to be executed? In practice one can seldom answer such a question definitely because it is just as difficult as deciding where to place microphones in a real room when making a wet recording of a pipe organ. However, the problem is not insurmountable by any means because of the range of adjustment offered by most effects processors. Effects processors exist either as separate boxes of hardware or as software modules running on a computer, though the former use much the same software techniques as the latter so they are both the same as far as this article is concerned. Real reverberation in a real room is a filter applied between the sound source (a pipe organ in this case) and the listener or a microphone. One way of simulating this deceptively simple system is to measure what is called the impulse response of the filter (i.e. the acoustic impulse response of the room containing the organ), and then to use this in an effects processor which uses a mathematical process called convolution. Convolution takes the source waveform from the simulated organ as its input and delivers a 'reverberated' version of it at the output.. The impulse response only has to be measured once, whereas convolution has to be applied continuously as a real time running process each time we want to simulate the effect of the room on the original sounds. Most reverberation processors are convolvers which use convolution in one form or another, though it will not be described further here because it involves some rather arcane mathematics. The subject of the impulse response itself does deserve further discussion though.
Measuring the impulse response of a room requires that one first has to decide on the location of a sound source which is to radiate a test waveform, and then choose the location of a listening position, which in practice is the position of one or more remote microphones which will pick up the test signal after the reverberant properties of the room have been impressed on it. One therefore immediately has the problem of how to select these two positions out of the near-infinite number that exist. For present purposes one would presumably choose the source location to be close to a pipe organ if one was present, but the choice of microphone position(s) is subject to all the uncertainties of listening position already mentioned several times in this article. These factors are important to bear in mind when using commercial effects processors, because one will seldom know how the impulse response was measured, if at all - it might simply have been dreamed up as a mathematical entity using synthetic parameters. Thus one usually has to make do with vague descriptions of the chosen type of reverberation such as 'large hall', etc. Fortunately, the number of controls in a high quality effects processor enable the simulated reverberation to be adjusted within wide limits. Such controls include the delay time between an input and the arrival of the first simulated reflected signal, high and low pass filters defining the frequency band of the reverberation signal alone, the stereo mix of the reverberation signal alone, its proportion relative to the input (wet/dry mix), simulated room size in terms of colouration, room size in terms of reverberation time, a 'distance' parameter as discussed above relating to colouration, etc.
The test source used for measuring the impulse response of a room has to radiate a signal at all frequencies of interest over the audio frequency range, and often it is indeed merely a very short impulse. Such signals possess energy at all frequencies up to a limit related to the duration of the pulse, therefore the general rule is that shorter is better. However, because of the short duration of the impulse, it is necessary to pack as much energy as possible into it so that an adequate signal to noise ratio at all frequencies will be obtained at the recording position. This is not straightforward, and only those methods using some form of relatively high-power explosion are practical. Note that the often-used and widely discussed hand-clap is next to useless - it is not loud enough to overcome the signal to noise problem, and its duration is too long to excite sufficient reverberation at the higher frequencies. Suitable short impulses can be derived from a high power electric spark jumping between electrodes (i.e. a miniature lightning discharge), a starting pistol or an electrically-detonated firework of some sort such as a theatrical maroon. The received signal is then, by definition and without further processing, the impulse response of the room for the chosen source and receiver positions. Nevertheless it is worth making the point that the power density per unit frequency of the received signal across the entire audio range can still be too low even when using loud acoustic impulses. This means that the signal to noise ratio of the impulse response can still be too small in relation to that of the samples which are to be convolved with it, because these will typically have at least 16 bits resolution and sometimes more. Therefore one has to be careful that the sample set, in which one will usually have invested much money, time and effort, is not degraded by passing it through an effects processor which uses impulse response data of lower quality. This is one reason why artificial reverberation can sound so unpleasantly noisy, often particularly noticeable during the simulated reverberation decay when the sound source (input signal) has ceased. In these circumstances one continues to hear a signal decaying into its own easily-audible quantisation noise floor because the signal to noise ratio of the recorded impulse response is inadequate.
To improve this situation, another technique is not to use an impulse but a source of continuous white noise, which also contains all the necessary frequencies within it. This can be radiated by a loudspeaker at more or less any desired sound level within practical limits, the received signal then being processed to derive the impulse response using Fourier Transform techniques. This can be done by the effects processor itself, and it can be more computationally efficient than convolution as well as providing a potentially better signal to noise performance.
Polyphony implications of wet sampling
The single essential difference between wet and dry sampling is that wet samples are used when it is desired to capture ambience as well as generated sound. It is an open question as to whether this confuses these two very different processes of sound generation and ambience retention, and people have different ideas about its desirability. Some issues have already been discussed including choice of microphone position and the consequential ambiguousness of ambience, the need to handle multiple release transients, and the inability to 'turn the reverb off'. In other words, once wet samples have been recorded there is no practical means of de-convolving them to get back to the original sounds. This is unlike the greater flexibility offered by dry sampling in that virtually any form of ambience can be added later if desired. However another important issue when replaying wet samples concerns synthesiser design in that significantly greater polyphony will often be required. This is merely because each note generator within the synth cannot be released until each un-keyed sample has decayed into inaudibility, and this typically might take several seconds. During this period new notes will usually continue to be keyed, resulting in a potentially rather large polyphony requirement which will be significantly larger than the number of simulated pipes sounding simultaneously. Therefore this is another reason as to whether a rendering engine (the synthesiser) ought to be called upon to simulate ambience and the sound of organ pipes at the same time. The answer to the question essentially boils down to a personal judgement.
Memory implications of wet sampling
A further implication of a decision to use wet samples relates to the size of the sample set in terms of its memory requirement. Each sample must include the reverberation tail after the key has been released, and this alone can be several seconds in duration. Reverberation is usually specified in terms of RT60, the time taken for a test sound to decay by 60 dB or a factor of one thousand in amplitude. However this is far less than the dynamic range of the ear at well over 100 dB, therefore we must use a more demanding definition here which measures the actual time required for a reverberant sound from an organ to become perceptibly inaudible in practice. This is necessary because many samples will decay simultaneously when a loud chord on full organ is released, thus in general inaudibility will only be reached after a time rather longer than RT60.
The bit depth (the number of bits per sample) rendered by any synthesiser today will be at least 16 bits, which corresponds to a dynamic range of 96 dB. Because the SPL and thus the recorded amplitude of a sample decays approximately exponentially versus time after key release, this means that it decays linearly in terms of decibels. Therefore a sample which occupies the full 16 bits before key release could have a reverberation time up to RT96 where RT96 = 1.6 x RT60 before it decays into insignificance as far as the synthesiser is concerned. If 24 bit samples are used (a dynamic range of 144 dB), the maximum reverberation time becomes RT144 = 2.4 x RT60. A pragmatic solution is therefore to multiply the quoted or measured reverberation time (RT60) of a room by two, which is the mean of the factors 1.6 and 2.4. A typical concert hall might have an RT60 of 2.5 seconds, implying that the reverberation tails of the samples recorded in it will actually last for around 5 seconds as far as the synthesiser is concerned. The reverberation time of many cathedrals will be much longer. Considering that the duration of the sustain phase of each recorded sample might also be about 5 seconds, this means the memory requirement for each sample, and therefore for the entire sample set, will be doubled if the reverberation tails are to be properly rendered. This is a significant disadvantage which would not apply when using dry samples.
Phase and amplitude alignment at key release
You
might think that recording a wet sample and then reproducing it will
automatically capture the reverberation of the auditorium exactly. Well, it
won't. This is because, when playing the simulated organ containing this sample,
the performer releases the key at an arbitrary point on the stored waveform,
usually somewhere within its sustain section but sometimes (if the note duration
is very short) within its attack section. The synthesiser must then attempt to
'join' the waveform at the point of key-release to the start of the release
section which contains the reverberation tail, and it must do it within a single
sampling interval. Therefore the resulting sound is bound to be artificial to
some degree because the sample was originally recorded using a key-release point
which will not be the same, or probably not even close to, the myriad and
unpredictable key-release points encountered when the simulation is being
played.
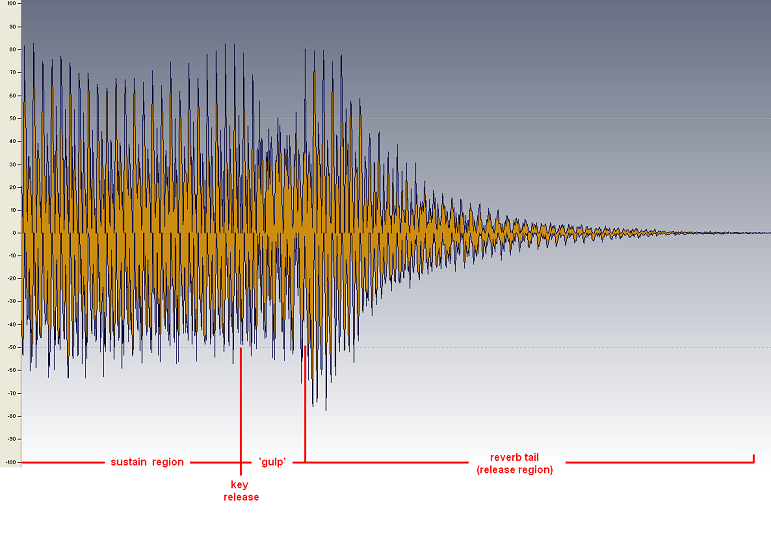
The undesirable effect described above can be seen in the waveform segment in Figure 3. This illustrates a chord held briefly before key-release at the instant shown. When the key is released the synthesiser then cross-fades the end of the sustain region into the start of the reverberation tail (release region), generating the visible 'gulp' owing to phase misalignment.
Figure 3. Illustrating the 'gulp' heard due to phase misalignment during the cross-fade at key release
It can also be heard in the audio clip below of the same wave segment:
Such effects occur frequently with some synthesisers when rendering wet sample sets.
At this point it is reasonable for readers to reflect the question posed by the title of this article back to me. Do I have a view as to which is better - a wet sample set or a dry one? Perhaps you will allow me to answer the question another way because it might sidestep the unhelpful controversies which otherwise get aroused. Therefore, let me answer the slightly different question as to whether one should strive to retain the ambience of the recording room in some manner. When posed this way, I am in no doubt that the answer is affirmative - it is undeniably a good thing. However there is more than one way to skin a cat, and it is not necessary to record wet samples in order to do it.
An alternative method, which is used by at least one well known manufacturer, is to record the pipes of the organ and the ambience of the room which houses it as separate exercises. This immediately gets around the considerable difficulties of designing a synthesiser to perform both of these almost unrelated functions simultaneously. As we have seen, the use of wet samples means we have to cater for the dependence of reverberation characteristics on note duration, build in considerably enhanced polyphony and memory capacity, accept the undesirability of replaying the samples in large listening rooms because of ambience conflict, choose microphone positions very carefully yet then accept that the recorded ambience is forever fixed, accept the fact one cannot adjust or turn the reverb off, and the other disadvantages rehearsed above. However the situation can be eased considerably if we simply design the synthesiser to cope only with dry samples and then add the ambience of the actual recording room from a separate effects processor. The ambience can be preserved in the effects processor by incorporating in it the impulse response of the recording room, not merely some vaguely defined generic one. The impulse response would be measured as outlined previously.
Few things in life are perfect of course, and this approach will still suffer from the generic disadvantages of effects processors which were also touched on above. However the advantages stem from two considerable benefits - synthesiser design is simplified, and the recorded ambience is adjustable within wide limits or it can be turned off altogether. There is also the satisfaction of knowing that the resulting virtual organ approaches the real situation more closely - the synthesiser emulates the pipe organ and the effects processor emulates the room, therefore both can be optimised independently. On the other hand, with wet samples, the several difficulties described above might cause some to conclude that the struggle to reproduce wet samples accurately is a battle lost before it begins, and it is a reflection of the undesirability of expecting a synthesiser to reproduce not only the pipe sounds themselves but the effect of the auditorium also. None of these problems arise if one uses dry samples and then imposes reverberation using an external effects processor. And one can also enjoy the freedom to adjust the ambience to taste in that case as well. Neither approach is perfect of course, but the choice boils down to minimising the evil.
It should be noted that the synthesiser will still need to be able to articulate the release characteristics of the simulated organ pipes even when it is only called upon to render dry samples. Removing the need to replay the reverberation tails of the recording room does not alter this necessity, even though it will often result in a dramatic reduction in the polyphony requirement..
Dry sampling is potentially a more flexible approach in that it can be used for digital organs situated in both wet and dry listening rooms without creating problems of ambience conflict. This will only arise if artificial reverberation is applied, but in this case the possible shortcomings of the effects processor itself (particularly an inadequate signal to noise ratio) also need to be considered. On the other hand, the ability to adjust effects processors is advantageous. Electronic versus acoustic signal mixing effects in the listening room need to be addressed because these will always arise when the number of loudspeakers is less than the polyphony figure of the instrument (in other words, they will always arise - period).
Wet sampling conveys an impression of the ambience of the recording room and therefore it is particularly applicable to dry listening rooms. Its use in wet ones is questionable because of the potential for confusion caused by ambience conflict in that situation. However even in dry listening rooms ambience conflict remains because they are not anechoic, therefore it suffers from most of the problems of recorded sound and stereophony in general. The fact that the impressed ambience cannot be removed is one such problem, and the fixed position of the microphone(s) during recording implies a lack of choice which some find objectionable in principle. The latter also leads to the possibility of phase interference impressed on the recordings which would not be so perceptually objectionable to a listener at the same position, and it requires careful consideration when designing the loudspeaker system in the listening room. However this is no different in practice to the signal mixing problem mentioned in connection with dry sampling.
An additional problem when using wet samples concerns synthesiser design. Simulating the different types of reverberation decay resulting from different note - sustain periods is difficult and only an approximation to the decay characteristics of the original recording room can be implemented (e.g. by designing a synthesiser which can handle multiple release points and multiple release transients). There is also a significantly enhanced polyphony requirement when reverberation times are long. Issues such as these call into question the desirability of attempting to simulate both the instrument and its acoustic environment in the one synthesiser.
Therefore both techniques have pros and cons and, overall, it could be argued that the issue boils down to one of flexibility, with dry sampling being more flexible than wet. However the flexibility can only be realised through the use of effects processors providing artificial reverberation, and because these introduce problems of their own, there seems to be no overall winner. However there is no doubt that one technique can be better than the other in particular situations and therefore, as with other aspects of digital organs which can only imitate the real thing at best, the user must decide which of the imperfect options is most attractive for a given application. Hopefully this article will assist in making the choice.
Digital organs using additive synthesis store the individual harmonics of a waveform instead of the waveform itself. The numbers stored are the amplitudes of each harmonic. When a note is keyed, all the harmonics are added together in real time as a set of sine waves for each stop currently in use. A widely used digital version of the technique was developed at Bradford university in the UK c. 1980, though it was first suggested as an electrical musical instrument simulation technique by Robert Hope-Jones as long ago as 1891 [4].
This is the subjective perceptual effect of a room endowed by its effects on acoustic waves, including reflection, echoes, scattering, absorption, diffraction and screening. Subjectively, two major factors which can be distinguished by the ear are reverberation and colouration. Ambience is discussed in detail in this article.
This is the subjective conflict which occurs when material recorded in one room is replayed in another with a different ambience. The problem is a long-acknowledged one for stereophony and surround sound and it also occurs for digital organs. It is discussed in detail in this article.
A room is anechoic if it imposes no effects due to its boundaries or surfaces on sounds, such as reflection, echoes, scattering and absorption. Also diffraction and screening do not occur because the objects which give rise to them in ordinary rooms are not allowed to enter anechoic ones. No real room used for music purposes is anechoic unless specially treated and intended to be so, even the smallest ones. Thus a small room with a dry acoustic is not generally anechoic.
This is a recording technique which uses a dummy head or bust, including carefully modelled outer ears (pinnae). Recordings are made using small microphones placed at the notional positions of the ear drums in the dummy head. When the recorded signals are replayed through headphones, a fair impression of the 3-dimensional aural perception experienced by a listener in an auditorium is obtained. It is obviously not a practical technique for use with digital organs if more than a few people besides the player are to hear the results.
Note that two loudspeakers do not provide the same effect as headphones on binaural recordings, even in an anechoic room, because each speaker provides signals to both ears, and in a non-anechoic room its ambience becomes important when speakers are used. Neither of these applies to headphone listening..
This is the alteration of the harmonic structure of a sound by the ambience of a room in that certain harmonics or groups of harmonics are enhanced or suppressed relative to their values in the emitted spectrum. Thus colouration is a form of distortion, though it is often perceived to be attractive. It is discussed in detail in this article.
This is the process whereby the effect of any filter on any input signal is represented mathematically. A non-anechoic (real) room acts as a filter placed between the sounds emitted within it and the place where they are received by a microphone or heard by a listener. Artificial reverberation implemented by effects processors often use convolution, and they are sometimes called convolvers.
This is the effect when sound waves meet a structure having one or more dimensions comparable with the wavelength. The waves tend to skirt or 'leak' round the structure in a way which would not occur if the wavelength was much smaller, in which case the structure would act as a screen by preventing most of the energy getting beyond it. If the wavelength was much larger than the structure it would have little or no effect, and the energy would continue to propagate beyond it as though it was not there. Another example of diffraction occurs due to the finite dimensions of sound-producing apertures such as organ pipe mouths and loudspeakers. This defines the angular width of the acoustic beam radiated from the aperture, the width getting narrower as the aperture gets larger. The beamwidth is also frequency dependent, becoming narrower as the frequency increases.
In the context of this article this has two meanings:
(a) Dry sampling is when the sounds of organ pipes are recorded by one or more microphones at short ranges. Because the sound pressure level is therefore higher than it would be at longer ranges, the recording level has to be set lower. This means that the ambience of the recording room which arises due to reflections, etc from distant surfaces gets suppressed. Generally the microphones are moved around to be close to the pipe being recorded at any one time to maximise the signal to noise ratio and minimise the ambience, and this means the relative volume levels of the pipes can be lost, i.e. the regulation characteristics of the pipe organ can also be lost unless steps are taken to retain the information (e.g. by making an additional recording from another microphone which remains fixed in position). Less frequently, dry sampling is also done in an anechoic room.
(b) A dry room is one having an acoustic ambience which imposes relatively little subjective modification on sounds heard in it. However this usually does not mean the room is anechoic unless it is specifically treated to be so.
These are diverse commercial hardware units or software modules which imposes various modifications on musical or other sound signals which are input to it. The range of effects is enormous in the digital music industry, but here it is mainly used to denote artificial reverberation and colouration. Effects processors are discussed more fully in the article.
This is the waveform that would be produced at an arbitrary listening position if a sound pulse of very short duration were to be emitted elsewhere in the room. It is discussed in more detail in the article.
In this article, this is the effect when two or more sound waves with different amplitudes and phases coincide at a given listening position or microphone position in a recording room. It is discussed in more detail in the article. It also occurs in the listening room when two or more signals are mixed, and this is called signal mixing in this article to distinguish the two situations.
This is a digital music synthesis technique which is discussed at length elsewhere on this website [5].
There is something approaching an infinite number of regions on the room boundaries where reflection of sound waves takes place. Reflection is rather like what happens to light when it hits a mirror in that the wavefront of the incoming wave is retained when it is reflected, and simple laws govern the angle between the incident and reflected waves. It is different to scattering, which results in energy bouncing off in all directions rather than in just one direction. Whether reflection or scattering is involved at a given region on the boundary depends on the ratio of surface roughness to wavelength of the sound. In practice, the term 'surface roughness' also includes objects such as furniture, not just the texture of finish on walls, floors, etc. As an example, a rigid cubic cabinet with dimensions around 1 m (around 3 feet) will start to reflect sound increasingly strongly at frequencies above about 350 Hz (the fundamental of an 8 foot stop near the middle of an organ keyboard), but it will scatter them below. At the lowest frequencies it will have no effect at all.
This is an important component of the subjective ambience perceived in a room. It is discussed in detail in this article.
There is something approaching an infinite number of regions on the room boundaries where scattering of sound waves takes place. It is different to reflection in that scattering occurs when the wavefront of the incident wave is not preserved – the scattered energy propagates in all directions when it leaves the surface. Scattering is also strongly frequency dependent. Whether reflection or scattering is involved at a given region on the boundary depends on the ratio of surface roughness to wavelength of the sound. In practice, the term 'surface roughness' also includes objects such as furniture, not just the texture of finish on walls, floors, etc. As an example, a rigid cubic cabinet with dimensions around 1 m (around 3 feet) will start to reflect sound increasingly strongly at frequencies above about 350 Hz (the fundamental of an 8 foot stop near the middle of an organ keyboard), but it will scatter them below. At the lowest frequencies it will have no effect at all.
In this article, this is the phase interference effect when two or more sound waves, or harmonics of them, with different amplitudes and phases are mixed electrically before being fed to a single loudspeaker in the listening room, or mixed acoustically within it. It is discussed in more detail in the article. Similar effects also occur in the recording room, and they are simply called phase interference in this article to distinguish the two situations.
In the context of this article this has two meanings:
(a) Wet sampling is when the sounds of organ pipes are recorded by one or more microphones at relatively long ranges. Because the sound pressure level is therefore lower than it would be at shorter ranges, the recording level has to be set higher. This means that the ambience of the recording room which arises due to reflections, etc from distant surfaces is also recorded along with the signal, and this is usually intentional. Generally the microphones remain fixed in position throughout the entire sampling process during wet sampling so that, among other things, the relative volume levels of the various pipes (and thus the regulation characteristics of the pipe organ) are preserved. Difficulties can then arise because of the large dynamic range of the sounds arriving at fixed microphones, such as those from a quiet dulciana compared to an ear - splitting tuba, and these can lead to problems of signal to noise ratio for the softer stops.
(b) A wet room is one having a subjectively obvious acoustic ambience, such as pronounced reverberation and colouration, which imposes a considerable subjective modification on sounds heard in it.
1. "Fundamentals of Musical Acoustics", 2nd edition, Arthur H Benade, Dover, New York, 1990.
2. "Making Recordings of Organ Stops" in the article "Voicing Electronic Organs", C E Pykett, currently on this website (read).
3. "Signal Mixing" in the article "The End of the Pipe Organ?", C E Pykett, currently on this website (read).
4. "Hope-Jones and the Pipeless Organ", C E Pykett, currently on this website (read).
5. "Physical Modelling in Digital Organs", C E Pykett, currently on this website (read).
|